
If you haven’t heard about ChatGPT, where have you been?
There’s been plenty of hype surrounding OpenAI’s automatic text generator and chatbot, including concern over the potential of this technology to impact review data, academia and veracity of online content. But how worried should we be, and what are experts doing to counter these threats?
Experts at Symanto Research review the current situation and reveal new and ongoing efforts to combat the risks of automatically generated texts.
How Realistic Are Auto Text Generators?
Can you tell if this review was written by a human or generated automatically by a neural network?
Hotel Cambrai is a hotel worth mentioning! As I told the owners, I need an alternative accommodation, so they did a great job to get it. But I would recommend this hotel to everyone, whether you are traveling in Thailand or not. Just because the building is old, does not mean that it does not have amazing properties, especially for travelers. I stayed here three times, it was great, they accommodated me, and also there was a lot to do while I was there (which was what I wanted!). Everything got organized with great staff, and I had a fantastic time. I can highly recommend Hotel Cambrai (I would also recommend booking a room online).
If you struggle to tell the difference between human and automatically generated texts these days, you’re not alone. Today, we are seeing the rise of massive deep learning models for automatic content generation, systems that perform faster and better than humans in many creative tasks. Examples of this include image generation from text prompts, which is becoming more and more popular every day, and, of course, language generation through neural language models.
We are seeing how large language models (LLMs) evolve through the years, improving in quality and gaining the ability to emulate human writing. This is clearly illustrated by the current fame of ChatGPT, an LLM that understands and carries out human instructions, can generate well-shaped text and code, and learns from user feedback.
This Technology Isn’t All That New
However, ChatGPT is not the first LLM that can achieve these tasks. For instance, the previous review was generated by GPT-2, a GPT model released in 2018 that is much less capable than the current ChatGPT.
There has been a long line of research with models such as GPT-2, GPT-3 and InstructGPT that lead up to this moment. Other open-source alternatives have also contributed to the milestone of understanding and generating text, such as the well-known BERT family of models, BART, T5, etc.
Potential Risks of Automatic Text Generators
These language models are currently being integrated into cutting-edge technologies beneficial to society, but there are many scenarios where they could hurt businesses and people. Examples include generating news articles or reviews that seem coherent but are untruthful or generating large quantities of text with the objective of appearing first in a search engine’s results.
While there have been large efforts to improve ChatGPT and its predecessors, there is still lots of work to be done in this regard. This is especially reflected in LLMs’ ability to hallucinate, generating text with nonfactual information, due to how it simply predicts the next most probable token given a prompt.
That is, LLMs are very sensitive to the prompts they are given, and their outputs could very easily be manipulated by malicious users to generate false, incorrect, or unverifiable information that can easily deceive us.
Take a look at these article headlines illustrating societal, business, and academic concerns regarding this technology. For this reason, many technology companies like Google, OpenAI, or Turnitin are developing their own solutions to detect the misuse of automatically generated text.
Examples of recent alarming news with the rise of ChatGPT.
At Symanto, we foresaw how these developments, culminating in high-quality automatically generated text that is not fact-checked, could represent a risk, and fool any reader.
To calculate the extent of the risk, the graph below illustrates the reachability of the current most popular language model, ChatGPT, which reached 1 million users (266 million visitors to date) several months before other popular broad-spectrum applications.
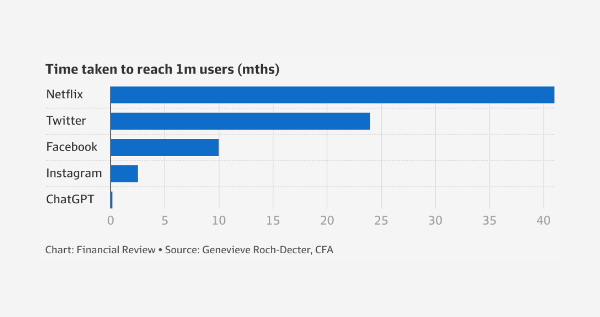
Time taken to reach 1 million users (in months).
If all of them were dedicated to misuse this technology, the reliability of the content on the internet, in academia, and in other scopes will be called into question.
Research and Investigation to Counter the Risks
This is why we are organising the AuTexTification evaluation campaign at IberLEF 2023, the 5th workshop on Iberian Languages Evaluation Forum in the SEPLN 2023 conference, one of the most important annual events on computational linguistics for Iberian languages.
With our AuTexTification, we aim to boost this line of research, finding new insights on the idiosyncrasies of these language models and studying the participant’s different approaches, their viability and performance on a wide variety of language models and text generation techniques.

AI generated image courtesy of Dreambooth.
Technology To Detect Automatically Generated Text
Additionally, we are actively developing technologies that can automatically detect generated content through our Symanto Brain platform. Symanto Brain is a no-code approach that includes fully customisable AI systems that provide you with text analytics and insights.
With Symanto Brain, you can automatically detect whether a text is generated or written by humans without having to resort to investing in resources toward building your own solution. To use Symanto Brain for generated content detection, you can just provide it with a small set of human texts labeled as human, and a few generated texts labeled as bot.
Together with other standard approaches to generated content detection, we will include Symanto Brain as a baseline in our AuTexTification shared task.
Try and See If You Can Beat It!
Get started with Symanto Brain today: try our free demo and see if you can detect whether text has been written by a human or an automatic text generator. Alternatively, get in touch for more information.
